python爬取今日头条评论,python3爬今日头条新闻 |
您所在的位置:网站首页 › 头条今日头条新闻 新闻 › python爬取今日头条评论,python3爬今日头条新闻 |
python爬取今日头条评论,python3爬今日头条新闻
|
前言
任何爬虫工程师在爬取网站数据之前都会对网站进行分析,并且进行逆向(js)破解(加密),所以我们在爬取今日头条的文章和视频数据之前,我们也需要先分析一下今日头条的反爬虫机制以及进行逆向(js)破解(加密)。 QQ群聊855262907 最新版本Python3爬取今日头条文章视频数据,完美解决as、cp、_signature的加密方法(2020-6-29版)Python3爬取今日头条文章视频数据,完美解决_signature的加密方法(2020-10-16版) 分析今日头条今日头条某用户的链接:https://www.toutiao.com/c/user/3410443345/#mid=3413306633 按F12弹出开发者界面,选择Network区域,你会发现有很多的请求链接,鼠标划到最上面,然后看到有一个跟网站URL一样的链接,点击进去用python画小猫。 AJAX请求是网站通过js脚本发起的请求连接,目的就是为了在不刷新网页的情况下就能实时的更新网页内容,从而在感觉上你是觉得他和网页源码拼接在一起。 我们再从众多的链接中进行筛选,由于AJAX的类型是XHR的,所以在开发者模式里面我们选择XHR,就能看到只剩下几个链接了,然后从这几个链接里面找出与网站内容极其相符的链接就可以了。 我们知道这个链接后就会要去请求这个链接,从而在里面获取到自己想要的数据,这样我们就获得了数据。 我们来看一下开发者工具中的Network区域的Headers区域,经过两次刷新网页会发现两次请求中的参数是有变化的,以及Request Headers的参数也是有变化的,看图。 第一次请求: 解释(百度百科):在Web应用程序中,系统的瓶颈常在于系统的响应速度。如果系统响应速度过慢,用户就会出现埋怨情绪,系统的价值也因此会大打折扣。因此,提高系统响应速度,是非常重要的。 Web应用程序做的最多就是和后台数据库交互,而查询数据库是种非常耗时的过程。当数据库里记录过多时,查询优化更显得尤为重要。为了解决这种问题,有人提出了缓存的概念。缓存就是将用户频繁使用的数据放在内存中以便快速访问。在用户执行一次查询操作后,查询的记录会放在缓存中。当用户再次查询时,系统会首先从缓存中读取,如果缓存中没有,再查询数据库。缓存技术在一定程度上提升了系统性能,但是当数据量过大时,缓存就不太合适了。因为内存容量有限,把过多的数据放在内存中,会影响电脑性能。而另一种技术,懒加载可以解决这种问题。 需要注意的Request Headers中cookie的参数(解决方法:手动获取这些参数的值): 参数作用变化加密tt_webid未知根据我的观察是一天变化一次是WEATHER_CITY标记城市不变化是(urlencode)tt_webid未知同上tt_webid一样是csrftoken用于csrf同上是这样就分析完整个网站了,下面开始实战。 爬取今日头条知道这些加密参数后就开始对加密参数进行破解 1.破解as和cp首先我们已经知道了每次的访问参数都在变化,所以我们要先找出这些参数的加密代码,也就是js代码。 搜索js文件中带有as或cp或_signature字符的文件,然后再分析代码是怎么构成的。 搜索方法: 其中i.as和i.cp分别对应as和cp,而i是由ascp.getHoney()这代码返回的,所以我们继续找ascp.getHoney,继续搜索getHoney函数。 根据这串JS代码将他转换为Python代码就可以得出as和cp的值了,下面给出Python代码: import math,time,hashlib def getHoney(): e = math.floor(int(str(time.time() * 1000).split('.')[0]) / 1e3) #获取13位毫秒数然后除于1e3再向下取整 i = str('%X' % e) #转换e为16进制 m5 = hashlib.md5() m5.update(str(e).encode('utf-8')) t = str(m5.hexdigest()).upper() #进行md5加密 if 8 != len(i): return {'as':'479BB4B7254C150','cp':'7E0AC8874BB0985'} o = t[0:5] n = t[-5:] a = "" r = "" for x in range(5): #交换字符串 a += o[x] + i[x] r += i[x + 3] + n[x] return {'as':"A1" + a + i[-3:],'cp':i[0:3] + r + "E1"} if __name__ == '__main__': print(getHoney())
根据上面破解as和cp时候的截图,我们可以看见生成_signature的值是t,而生成t的方法是TAC.sign(userInfo.id + "" + d.params.max_behot_time),所以我们要搜索TAC.sign()方法。 |
 我们将对今日头条链接进行详细的分析,以下为分析步骤:
我们将对今日头条链接进行详细的分析,以下为分析步骤: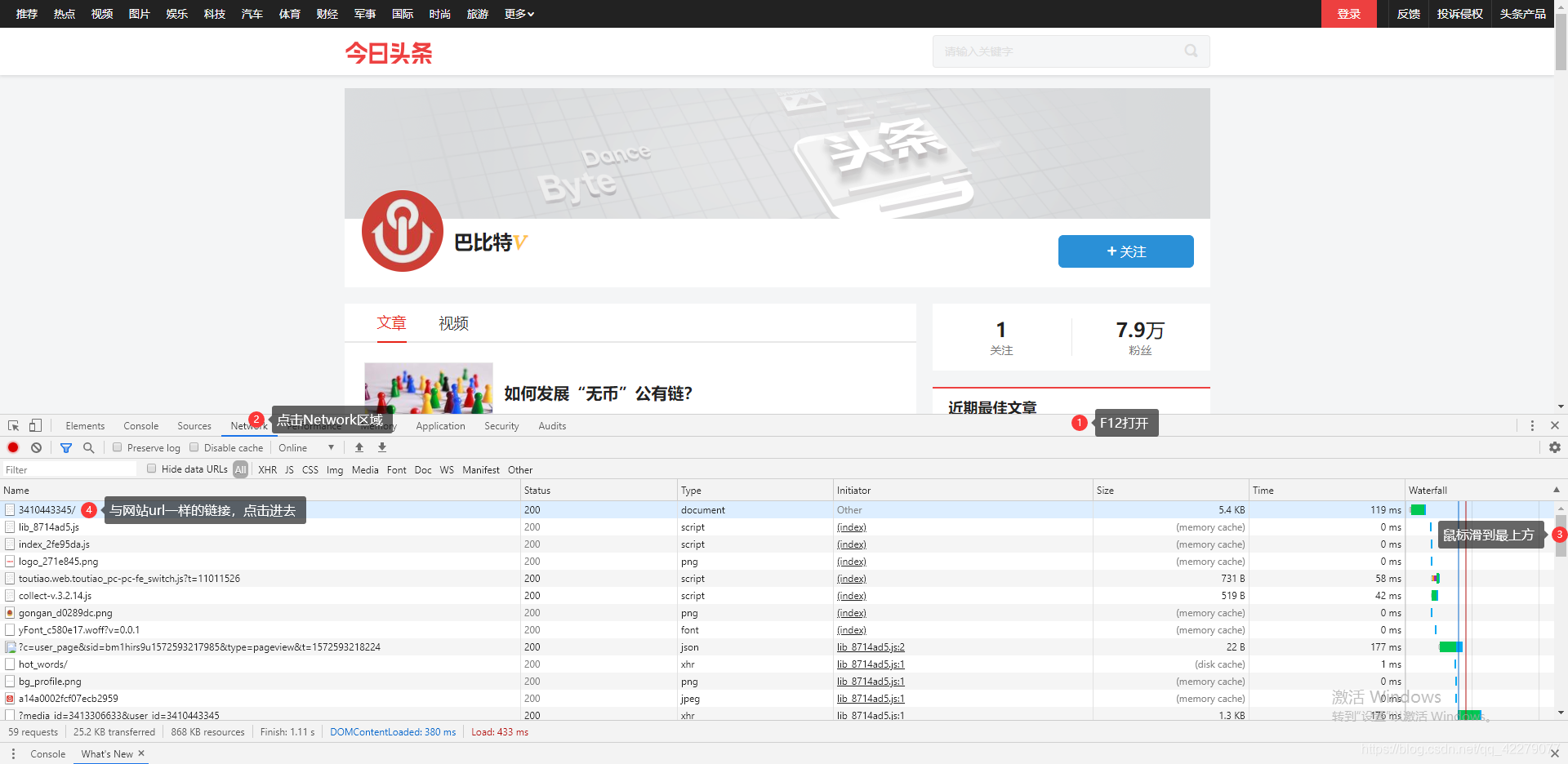
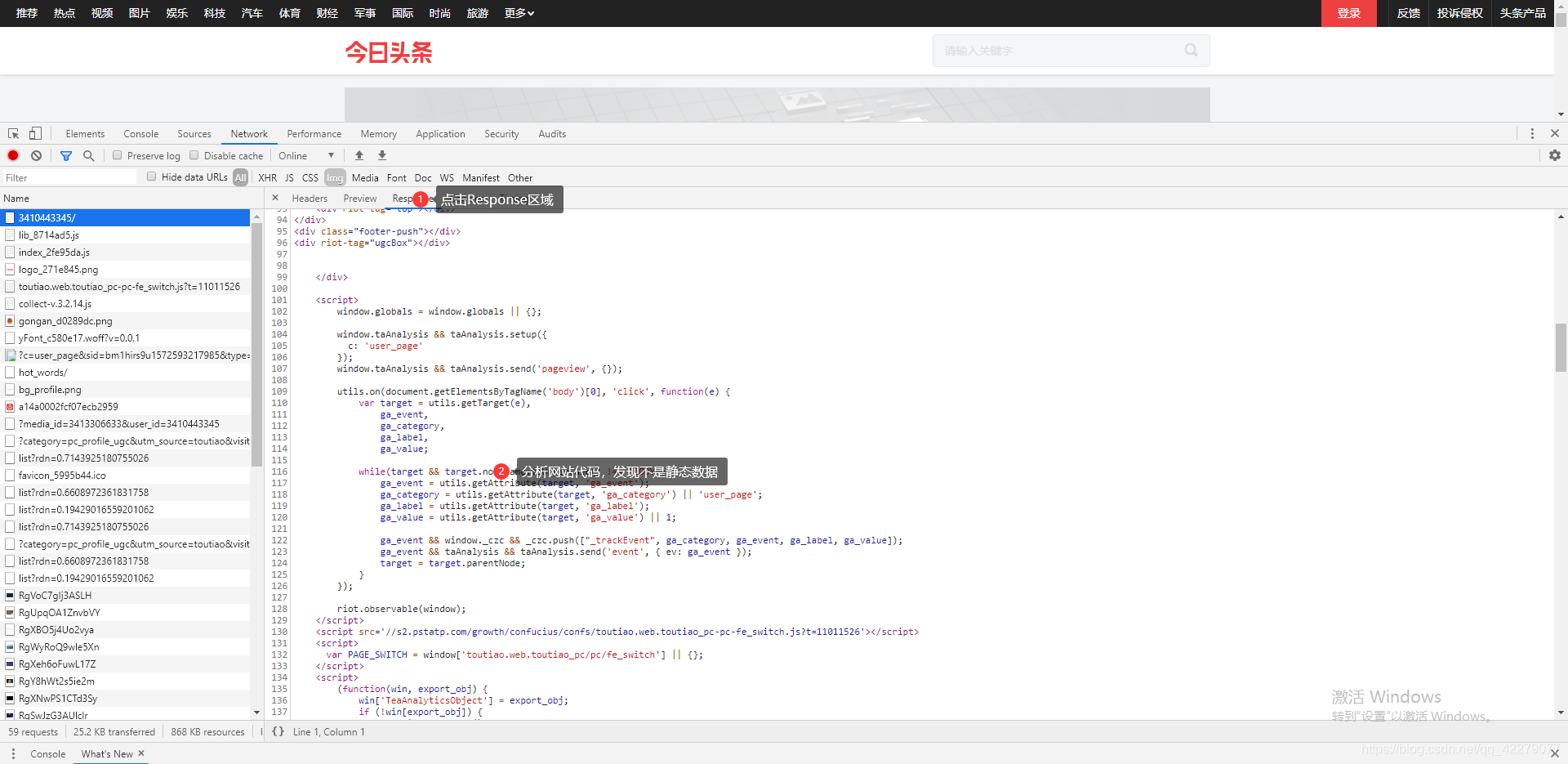 从这里得出今日头条网站的数据并不是静态数据,所以我们要进行下一步分析。
从这里得出今日头条网站的数据并不是静态数据,所以我们要进行下一步分析。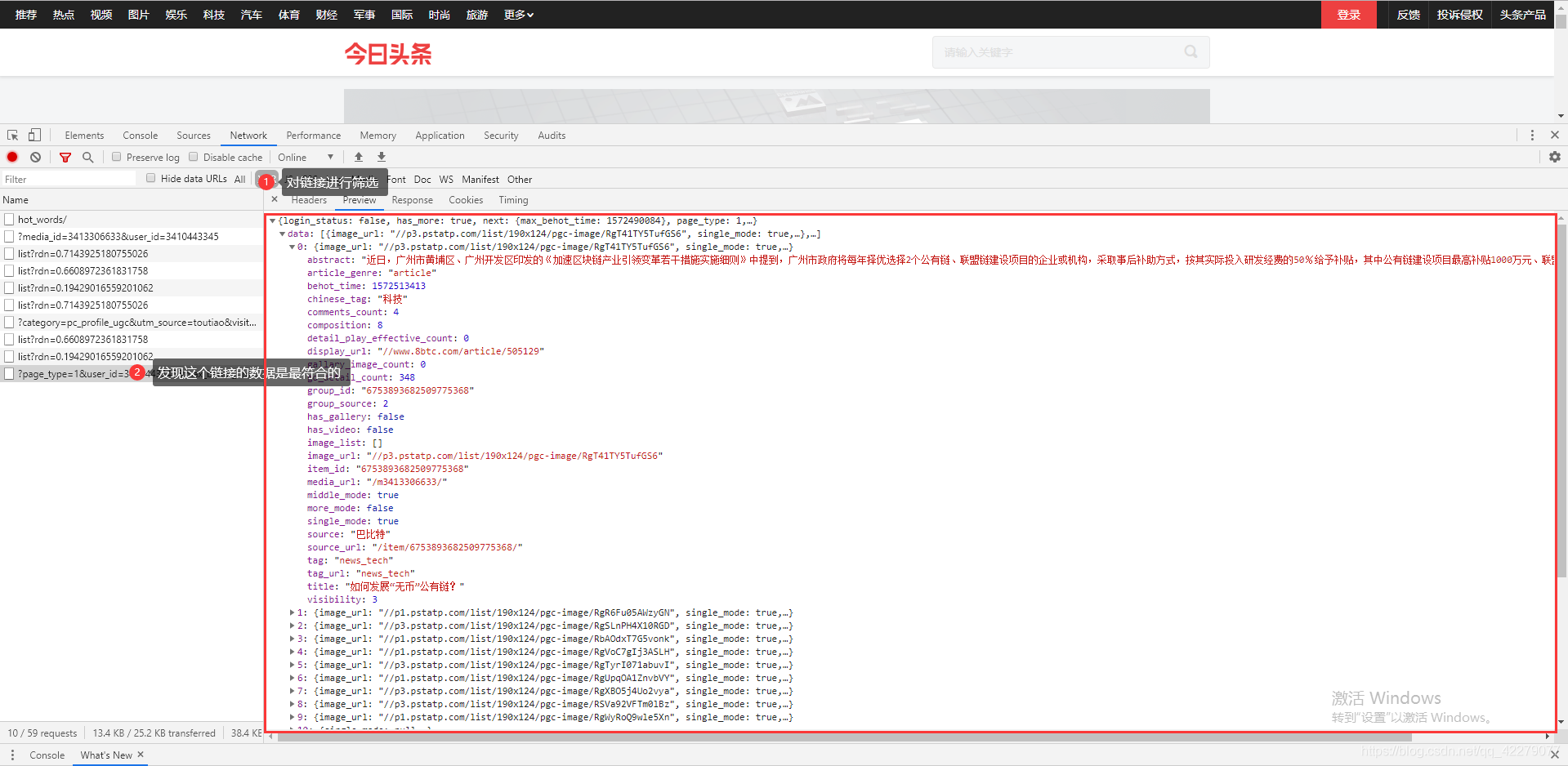 这样分析出来了网站的内容主要靠AJAX请求的数据来显示的。
这样分析出来了网站的内容主要靠AJAX请求的数据来显示的。
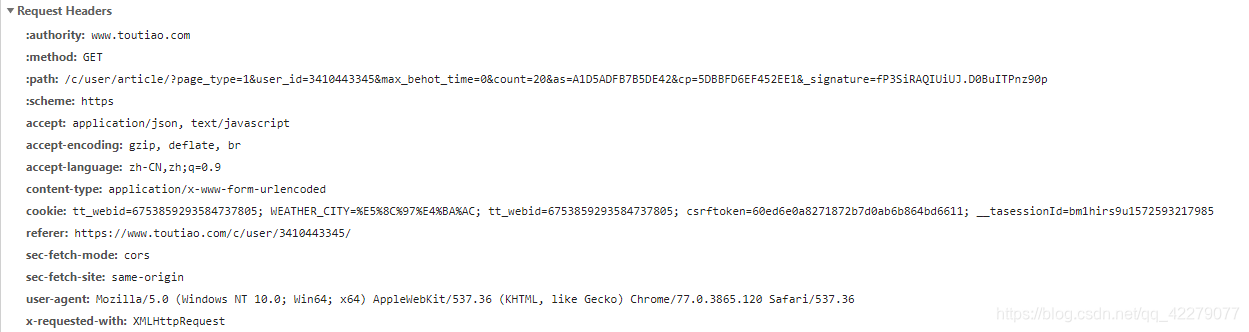 第二次请求:
第二次请求:
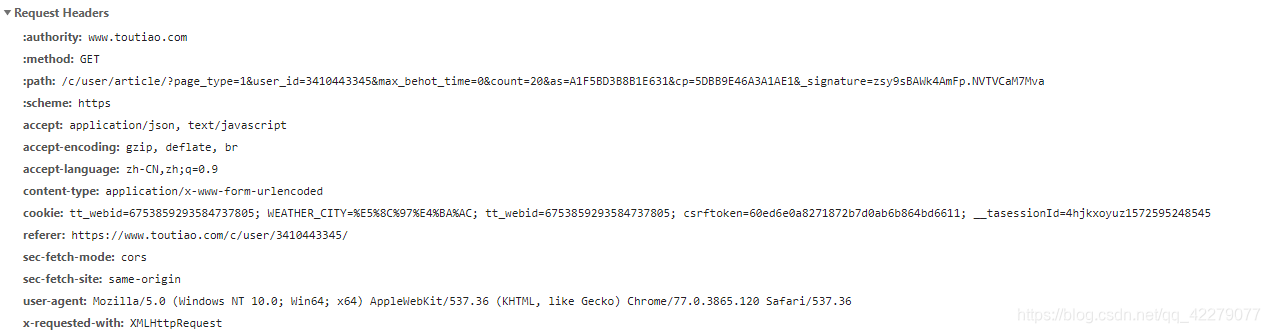 赖加载请求:
赖加载请求:
 从上面图片来看,我们就能发现链接的参数和请求的headers的参数是有变化的。 变化参数的作用:
从上面图片来看,我们就能发现链接的参数和请求的headers的参数是有变化的。 变化参数的作用: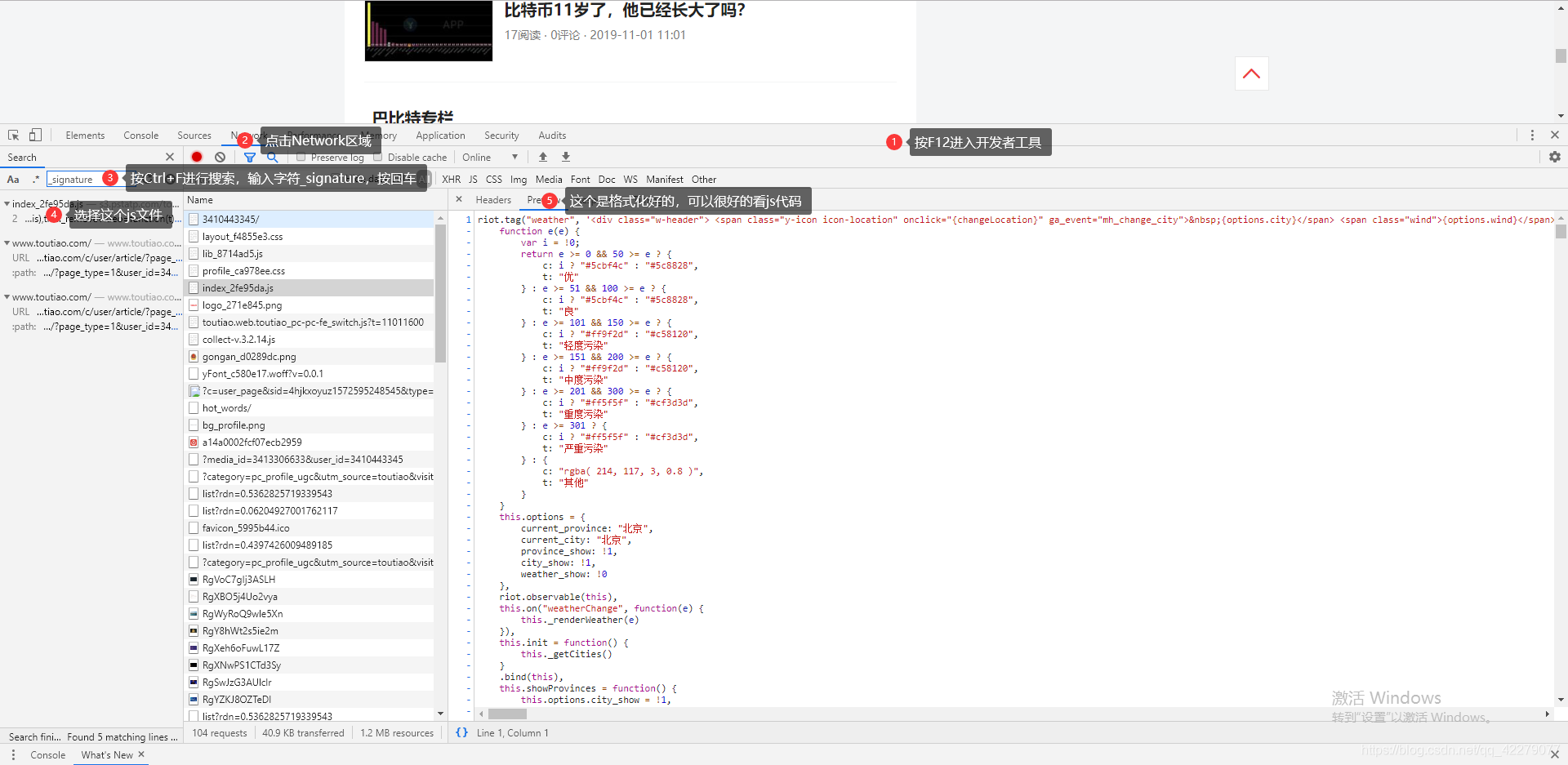 进入后再按Ctrl+F再次搜索_signature,就可以看到参数的加密方法了。
进入后再按Ctrl+F再次搜索_signature,就可以看到参数的加密方法了。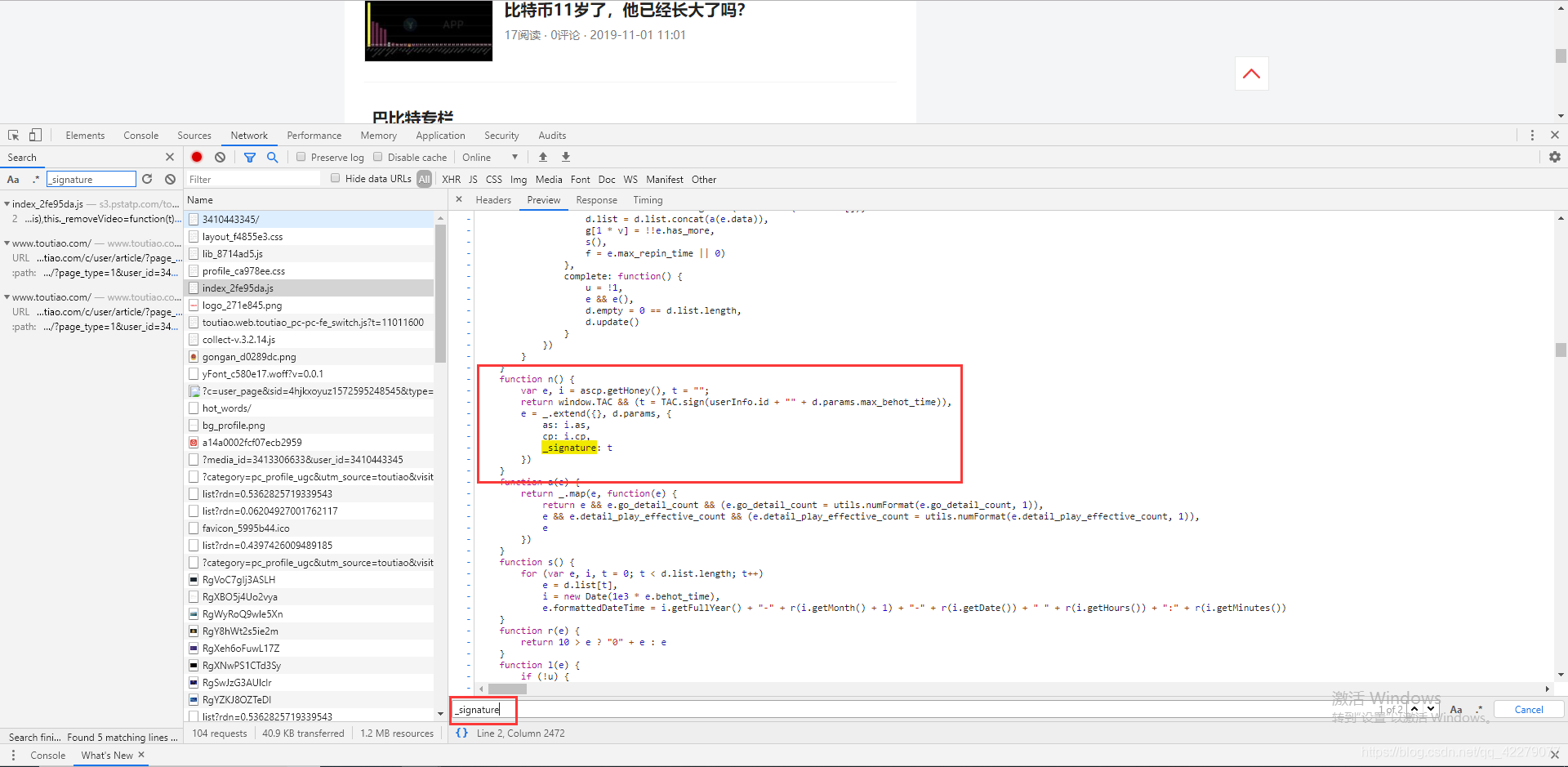 这样就能找到这串加密代码了。
这样就能找到这串加密代码了。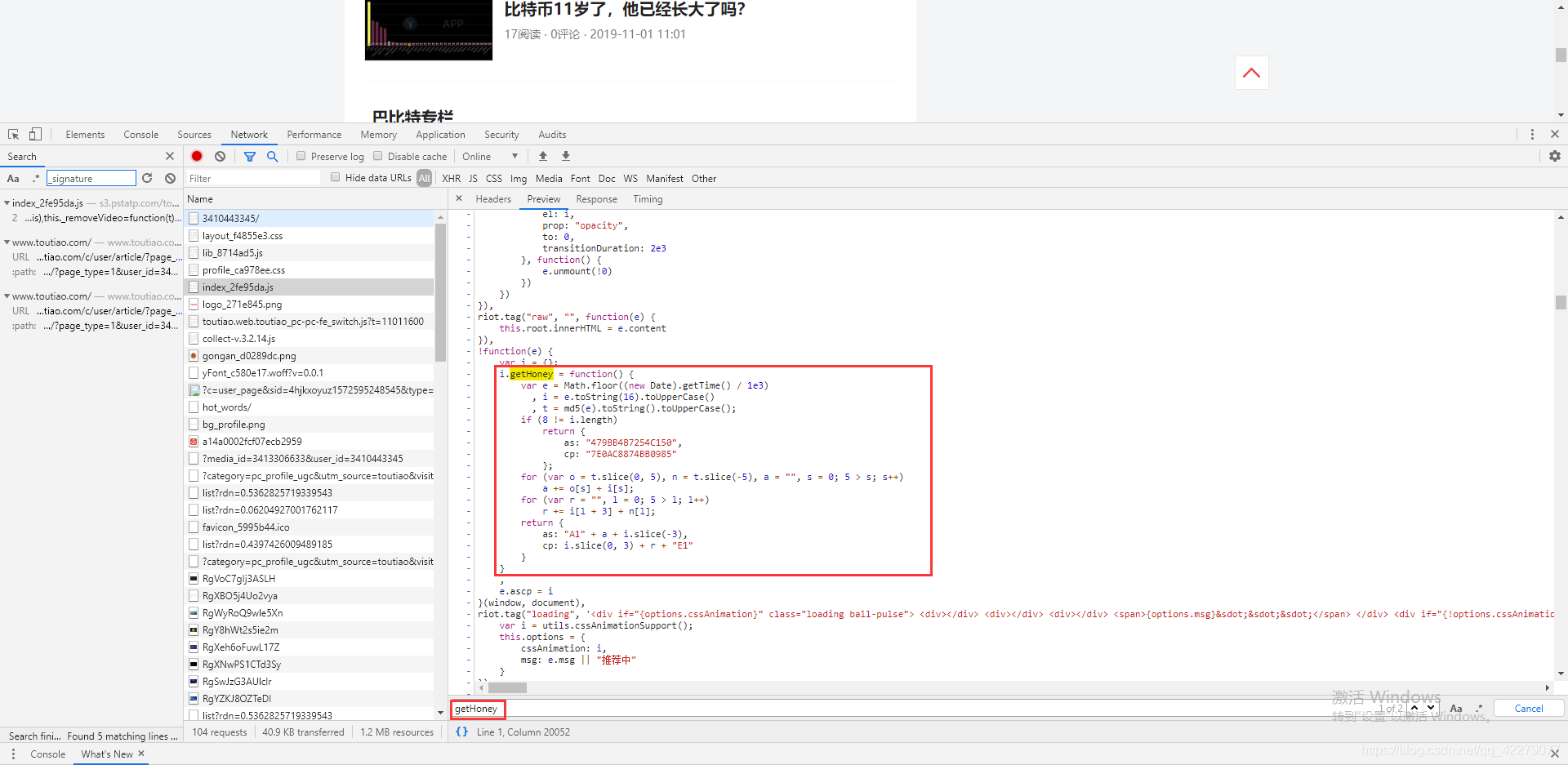

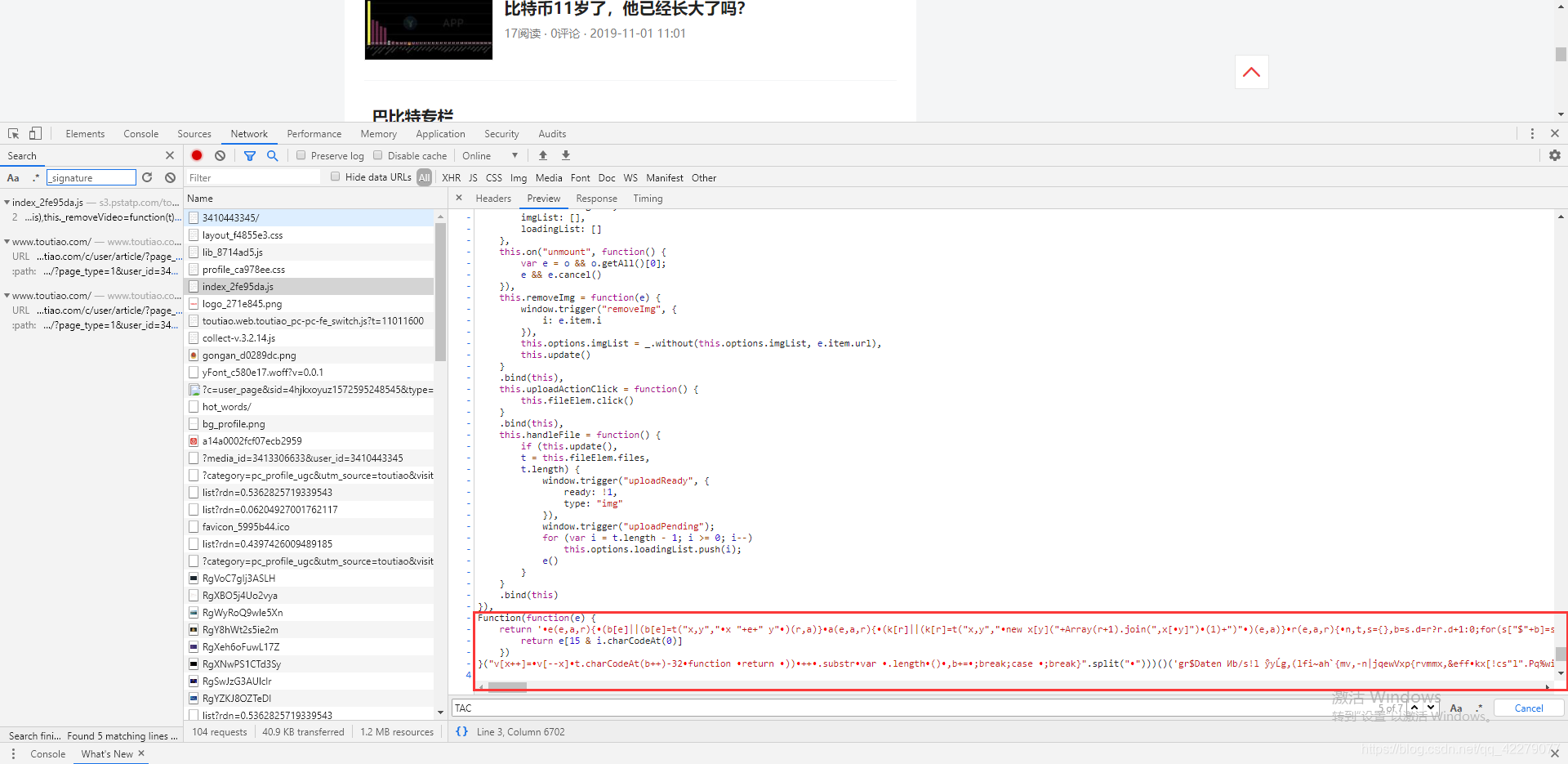 js源代码:
js源代码:【本文地址】
今日新闻 |
推荐新闻 |